
")
A continuación se presentan una serie de ejemplos ilustrativos del uso de la librería MineLink a través de la GUI DOPPLER.
El objetivo es mostrar de manera general la aplicación DOPPLER y sus características además de presentar ejemplos simples del uso
de algunas de las herramientas que pone a disposición.
Los tópicos a cubrir en este tutorial son los siguientes:
- Vista general y layout.
- Creando un nuevo proyecto.
- Generando precedencias.
- Generando nuevas columnas al modelo de bloques.
- Valorizando bloques desde DOPPLER.
- Calculando el pit final.
- Calculando pits anidados.
- Generando el gráfico Pit by Pit.
- Herramientas de visualización.
- Usando BOS2.
Vista general y layout
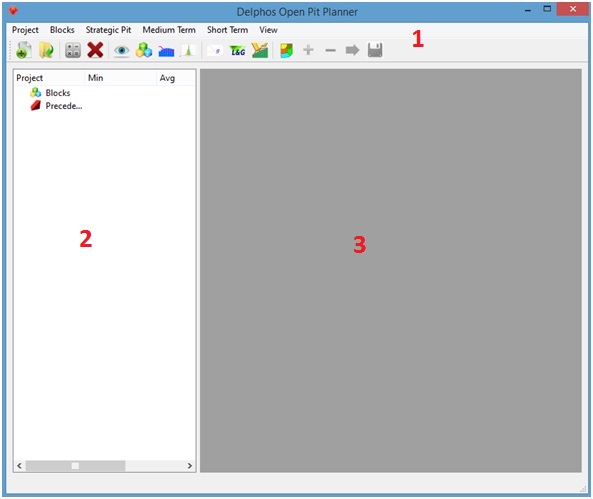
DOPPLER es una aplicación que puede presnetarse en 3 partes. La primera es la que se observa en la parte superior y que cuenta con un menu de acción y una barra de herramientas. La segunda es el panel de visualización de la derecha, en el cual se presentan las características generales del proyecto, tales como el modelo de bloques asociado, los diferentes conjuntos de precedencias que se van agregando por el usuario y una serie de datos con respecto a dichos objetos. Finalmente, el panel derecho es el panel de visualización en donde aparecerán todos los gráficos y/o diálogos necesarios durante el uso de la aplicación.
Creando un nuevo proyecto
El primer paso para crear un nuevo proyecto en DOPPLER es generar una nueva carpeta de trabajo para el proyecto en alguna ruta de elección. Una vez generada la carpeta, necesitamos un archivo de texto con nuestro modelo de bloques.
El archivo de texto con el modelo de bloques debe cumplir con las siguientes características:
- Regular. Es decir, todos los bloques poseen las misma dimensiones.
- Primera columna: Centroide en la dirección x.
- Segunda columna: Centroide en la dirección y.
- Tercera columna: Centroide en la dirección z.
- Cuarta a n-+esima columna: Columnas de atributos predefinidas por el usuario.
- El archivo debe estar en formato de columnas separadas por espacios o tabulaciones.
- La primera fila esta reservada para los nombres de las columnas. Los nombres de las tres primeras deben ser x, y, y z (en minúsculas) respectivamente. El resto se dejan a definir por el usuario.
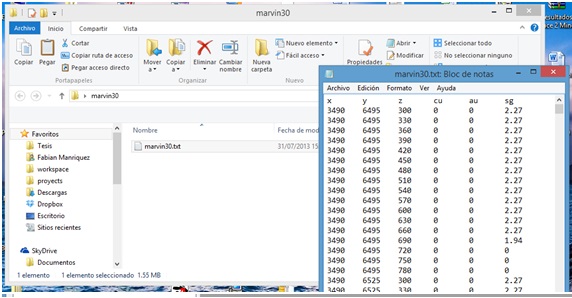
A continuación se entrega un ejemplo del formato de un archivo de modelo de bloques:
x y z cu au sg 3490 6495 300 0 0 2.27 3490 6495 330 0 0 2.27 3490 6495 360 0 0 2.27 3490 6495 390 0 0 2.27 3490 6495 420 0 0 2.27 3490 6495 450 0 0 2.27
El archivo de modelo de bloques puede encontrarse en la carpeta que generamos para el proyecto (recomendado) o en otra ruta.
Ahora procedemos de la siguiente manera. Primero vamos a Menu: Project->New:

Ahora nos aparecerá un cuadro de diálogo en el cual se nos solicitan tres rutas. La primera corresponde a la ruta donde se encuentra el archivo de modelo de bloques. La segunda corresponde a la ruta del archivo del proyecto. En nuestro caso dicho archivo no existe así que entregamos un nombre de un archivo inexistente con la extensión ".dp", recomendamos entregar la ruta de la carpeta creada para el proyecto (en la figura hemos seleccionado el mismo nombre del archivo de modelo de bloques en la ruta de la carpeta recién creada del mismo nombre). Finalmente, nos solicita la ruta de la carpeta (ya creada) del proyecto.
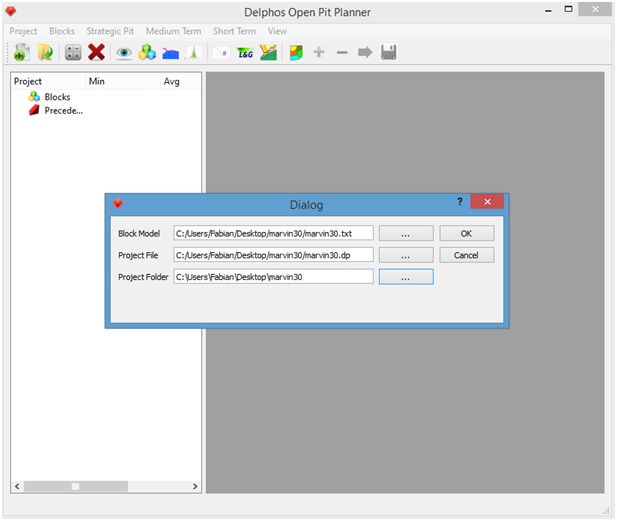
Ahora presionamos el botón "Ok" y esperamos a que se carguen los datos desde el modelo de bloques. Si la importación de los datos finalizó correctamente podremos ver un resumen de las columnas en el panel izquierdo de la aplicación.
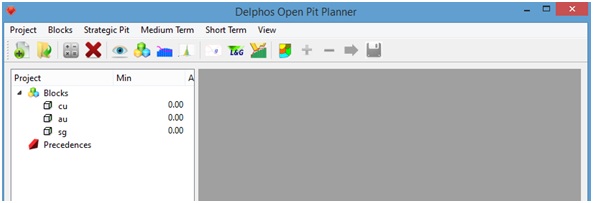
Presionando cualquier campo del panel izquierdo es posible (1) ver los datos importados desde el archivo de modelo de bloques en el panel derecho.
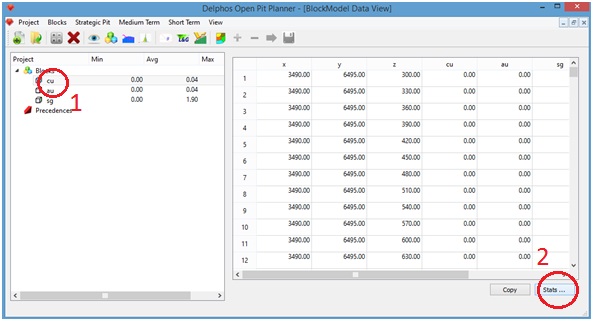
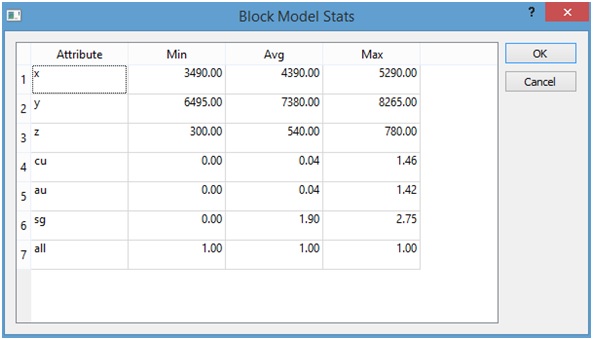
Presionando el botón "Stats" (2) se nos entrega un cuadro con las estadísticas básicas de los campos en el modelo de bloques.
Generando precedencias
Ya con un nuevo proyecto cargado podemos proceder a generar un conjunto de relaciones de precedencia entre los bloques de nuestro modelo. MineLink nos entrega la posibilidad de generar precedencias por ángulo de talud desde un punto de vista muy general: podemos para cada bloque en el modelo generar una rosa angular en el plano "xy" comprendida por sectores angulares disjuntos que completan el círculo completo (360° o 2pi radianes). Para cada uno de estos sectores podemos definir un ángulo talud distinto. El caso más simple es aquel en poseemos el mismo ángulo de talud para todos los bloques del modelo en todo el plano "xy". Es este el caso que mostraremos a continuación.
Como se señaló en el párrafo anterior, las precedencias pueden construirse desde un punto de vista muy general, por eso para el caso simple necesitaremos agregar una columna dummy en el modelo de bloques, con el mismo valor para todos los bloque del modelo, para indicarle que todos los bloques pertenecen al único sector angular comprendido entre el ángulo 0 y el ángulo 360°. Esto también nos entrega una primera idea de cómo agregar columnas al modelo de bloques a través de DOPPLER.
Vamos a Menu: Blocks->New Column
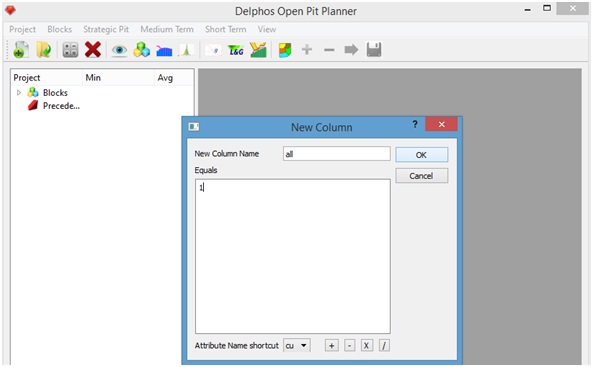
Nos aparecerá un cuadro de diálogo en cual debemos entregar un nombre para la nueva columna ("all" en nuestro ejemplo) y en cuadro inferior podemos entregar el valor para dicha columna (como podemos ver en "Generando nuevas columnas" este cuadro nos permite ingresar funciones que toman como argumento las columnas ya existentes del modelo de bloques), que en nuestro caso será el valor 1 (podría ser cualquier número real). Luego presionamos "Ok".
Ahora, una nueva columna denominada "all" debe aparecer en el panel derecho de la aplicación, bajo "Blocks". Ahora vamos a Menu: Blocks->New Slope
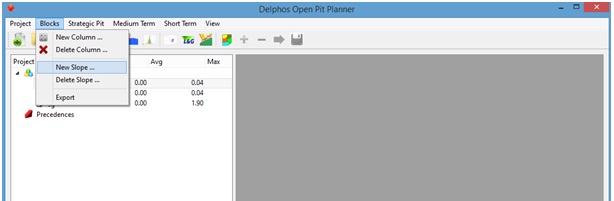
Un nuevo cuadro de diálogo aparecerá, en cual se nos solicita un nombre para el conjunto de precedencias a crear, un valor de la distancia a considerar para la cantidad de niveles a considerar para la construcción del cono de arcos, el nombre del atributo del modelo de bloques que indica el conjunto al que pertenecen los bloques, el valor a considerar dentro de la columna para esta selección y los sectores angulares a considerar para nuestro conjunto de bloques. Como ya establecimos, en nuestro caso entregaremos los siguientes valores para los parámetros:
- Z diff: 120 m (corresponde a precedencias a 5 niveles - 30*(5-1) -, ya que el tamaño del bloque en dirección z es de 30 m).
- Block model attribute: all
- ID: 1
- Angulo global de talud: 45 en todas las direcciones.
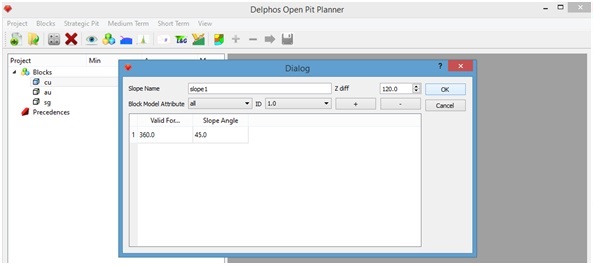
Los botones "+" y "-" sirven para agregar-quitar sectores angulares en la selección. Lo importante es que los sectores definidos sean una partición válida del intervalo [0,360] en el campo "Valid for". A modo de ejemplo, si vamos a considerar que todos los bloques entre entre 0 y 180 poseen un ángulo de 45, aquellos entre 180 y 270 un ángulo de 60 y aquellos entre 270 y 360 un ángulo de talud de 50, entonces la primera fila debería ser 180 para el primer campo y 45 para el segundo, la segunda fila debiera tener 180 en primer campo y 60 en el segundo, y la tercera fila debiera tener un valor de 270 en el primer campo y 50 en el segundo.
Al presionar "Ok" se procede a calcular las precedencias las cuales deben ser visibles desde el panel izquierdo bajo"Precedence".
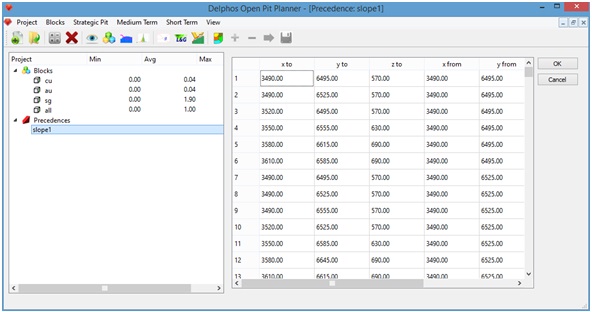
Generando nuevas columnas
Como se ve en la sección "Generando Precedencias" DOPPLER permite generar columnas en el modelo de bloques. Como un ejemplo más general al visto en dicha sección, generaremos una columna de tonelaje para nuestro modelo de bloques a partir de la columna "sg" que ya se encuentra en nuestro modelo. Asumiremos que dicha columna representa la densidad volumétrica de cada bloque.
Vamos a Menu: Blocks->New Column:
Como nuestro modelo posee dimensiones 30[m]x30[m]x30[m] para cada bloque, podemos ingresar la fórmula de cálculo del tonelaje a partir la columna de densidad ("sg") de la siguiente manera
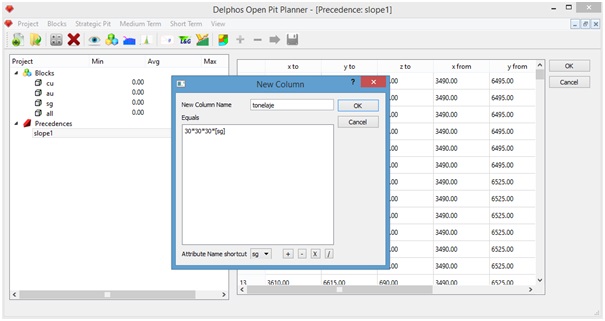
Presionamos "Ok" y nuestra nueva columna debiera ser visible desde el panel izquierdo, bajo "Blocks" con el nombre ingresado el cuadro de diálogo ("tonelaje" en nuestro ejemplo).
Valorizando bloques
Como se puede apreciar en las secciones "Generando Precedencias" y "Generando nuevas columnas", DOPPLER dispone de herramientas para generar nuevas columnas al modelo de bloques a partir de las columnas ya existentes. Lo anterior nos lleva pensar de inmediato en la posibilidad de realizar la valorización de los bloques de un yacimiento a rajo abierto desde DOPPLER.
Supongamos que disponemos de los siguientes parámetros para nuestra valorización:
- Precio cobre: 2.5 [USD/lb Cu]
- Recuperación metalúrgica: 0.85 (en tanto por uno)
- Factor de conversión 2204.6 [lb/t]
- Costo de venta: 0.12 [USD/lb Cu]
- Costo Mina: 1.6 [USD/t]
- Costo Planta: 10 [USD/t]
- Ley: [cu]
- Tonelaje bloque: [tonelaje]
Aquí estamos suponiendo que nuestro modelo de bloques cuenta con con la columna de ley de cobre [Cu] y la columna de tonelaje [tonelaje].
Nos dirigimos a Menu: Blocks->New Column:
Considerando la fórmula de cálculo usual y los valores previamente señalados, nuestra ecuación de cálculo se ve como
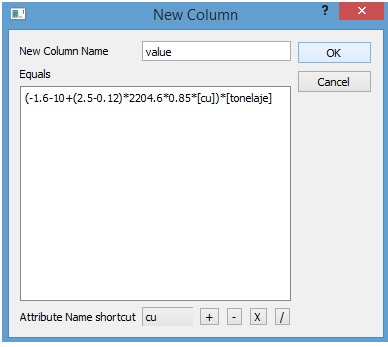
Nótese que hemos llamado "value" a nuestra columna de valorización y que cada vez que llamamos a una columna del modelo de bloques lo hacemos con su nombre entre corchetes. Presionamos "Ok" y podremos ver a nuestra nueva columna desde el panel izquierdo, bajo "Blocks".
Calculando el pit final
Para el cálculo del pit final necesitamos de una columna en el modelo de bloques que represente el valor de cada bloque. Esta columna puede encontrarse en el modelo de bloques desde un comienzo, o ser creada por el usuario (véase por ejemplo la sección anterior). Además necesitamos de un conjunto de precedencias previamente generado por el usuario (véase "Generando Precedencias").
Suponiendo que disponemos de dicha columna ("value" en nuestro caso) y del conjunto de precedencias ("slope1" en nuestro caso) procedemos de la siguiente manera: Menu: Strategic Pit-> Final Pit
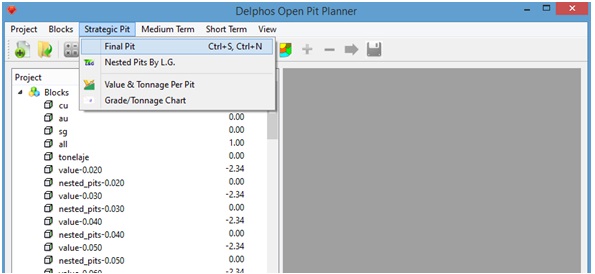
Nos aparecerá un cuadro de diálogo en cual debemos seleccionar el nombre de la columna del modelo de bloques la cual será utilizada como valor, el conjunto de precedencias a utilizar y el nombre del atributo binario que será creado en el modelo de bloques indicando si el bloque se encuentra (1) o no (0) en el pit final.
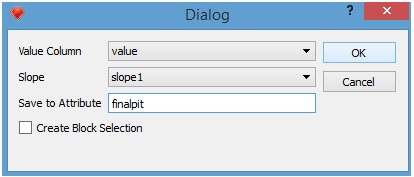
Al presionar "Ok" se resuelve el problema del pit final y se genera la columna binaria estipulada en el cuadro de diálogo, la cual es accesible desde el panel izquierdo, bajo "Blocks".
Calculando pits anidados
DOPPLER además permite aplicar el algortimo de pits anidados según Lerchs y Grossman. Como datos iniciales mínimos sólo necesitamos un conjunto de precedencias asociados a nuestro modelo de bloques previamente creado en DOPPLER (véase "Generando Precedencias"). Dado lo anterior, procedemos como sigue, vamos a Menu: Strategic pit-> Nested Pits by L.G.
Nos aparecerá un cuadro de diálogo el cual debemos llenar con los parámetros deseados. Para nuestro ejemplo supondremos los siguientes valores:
- Precio cobre: 1.7 [USD/lb Cu]
- Recuperación metalúrgica: 0.85 (en tanto por uno)
- Factor de conversión 2204.6 [lb/t]
- Costo de venta: 0.12 [USD/lb Cu]
- Costo Mina: 1.6 [USD/t]
- Costo Planta: 10 [USD/t]
- Ley: cu
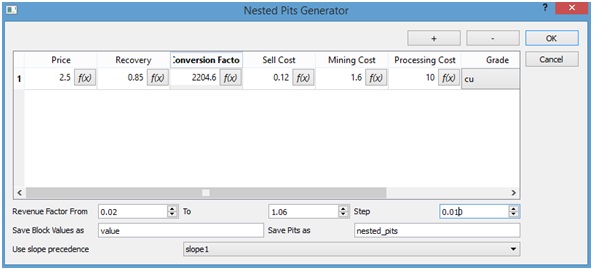
Como puede apreciarse en la figura anterior, el Revenue Factor se ingresa en forma de un intervalo (From-To) con un paso (Step). Además se solicita ingresar un prefijo para el nombre de las columnas de valor a crear para cada paso de factor en el intervalo señalado y un prefijo para los nombres de las columnas en que se guardarán las sucesivas soluciones del pit final para cada paso. Finalmente se pide seleccionar un conjunto de precedencias existente (vease "Generando Precedencias"). También se puede apreciar que en cada campo de la tabla que se ve en la figura se puede ingresar una fórmula de cálculo en vez de un valor fijo a través del botón "f(x)" (para una idea de cómo usar ésto véase "Generando nuevas columnas"). Presionando "Ok" se da inicio al algoritmo y un cuadro de avance se mostrará en pantalla.
Al finalizar el proceso, todas las nuevas columnas serán visibles desde el panel izquierdo, bajo "Blocks".
Gráfico Pit by Pit
Una herramienta de gráfica de utilidad cuando se resuelve el problema de los pits anidados es el gráfico "Pit by Pit". El cual reporta reporta para cada pit anidado (generado por un revenue factor) el tonelaje y el valor del pit. Claramente esta herramienta en DOPPLER necesita que se haya resuelto el problema de los pits anidados previamente (véase "Calculando los pits anidados") y un columna de tonelaje en el modelo de bloques.
Selecicionamos Menu: Strategic Pit-> Value & Tonnage per Pit
A continuación aparecerá un cuadro de diálogo en el cual se nos solicita ingresar, respectivamente, el nombre del prefijo común a las columnas de solución generadas por la resolución de los pits anidados (véase "Calculando pits anidados"), el prefijo de las columnas de valor asociadas a dicha resolución y el nombre de la columna de tonelaje en el modelo de bloques. Si nos basamos en el ejemplo mostrado en "Calculando pits anidados", entonces los valores a ingresar se muestran en la siguiente figura.
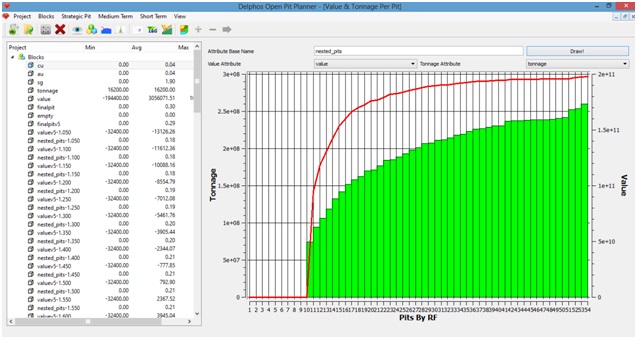
Una vez ingresados los valores se presiona el boton "Draw!" y se obtiene un gráfico como el que se aprecia en la figura anterior.
Herramientas de visualización.
DOPPLER posee dos herramientas de visualización para los datos del modelo bloques. La primera es la visualización de los bloques según un atributo del modelo de bloques. En este caso debemos seleccionar Menu: View->Blocks
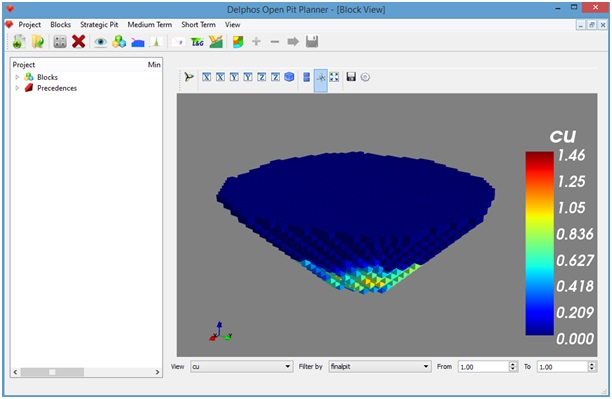
Se abrirá un panel al lado derecho. Para efectos del ejemplo supondremos que disponemos de una columna en el modelo de bloques llamada "finalpit" y una columna de ley de cobre llamada "cu".
Para visualizar se debe decidir primero:
- El campo que se debe filtrar: finalpit
- El campo que se desea ver: cu
- From: 1.0
- To: 1.0
Estas opciones se eligen en la parte inferior del panel derecho (ver figura siguiente).
Con los dos campos anteriores de ejemplo se está visualizando el pit final (previamente calculado, véase "Calculando el pit final") y visualizando la ley de cobre, como se ve en la siguiente figura. El intervalo From y To definen los bloques que cumplen con el campo filtrado entre estos dos valores definidos. Como hemos seleccionado desde 1 hasta 1, corresponden, según la convención adoptada en la sección "Calculando el pit final", a todos los bloques extraídos. Si por ejemplo hubiéramos seleccionado desde 0 hasta 1, hubiéramos obtenido una visualización de todos los bloques del modelo de bloques.
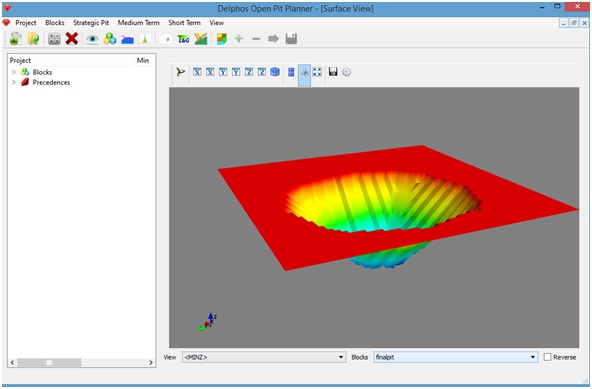
La segunda opción de visualización corresponde a la visualización de superficie. para acceder a ella, seleccionamos Menu: View->View Surface
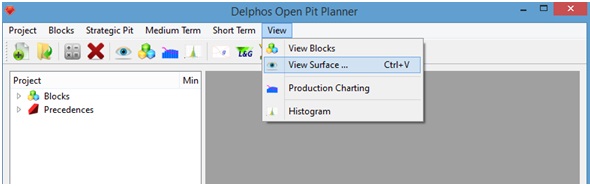
Se abrirá un panel al lado derecho.
Para visualizar se debe setear las siguientes opciones en la parte inferior del panel derecho:
- View: <MINZ>
La selección anterior corresponde al envolvente inferior del conjunto de bloques a seleccionar. Blocks: Corresponde al campo de pit que se desea ver. Ejemplo: finalpit. Nuevamente estamos asumiendo que poseemos una columna binaria en el modelo bloques llamada finalpit. En el caso de la visualización de superficie, DOPPLER, por defecto selecciona los bloques de valor 1 como conjunto a visualizar.
Usando BOS2
DOPPLER provee de un módulo que permite usar BOS2. Para hacer uso de este módulo sólo necesitamos de modelo de bloques con las columnas apropiadas. Para seguir de mejor manera este ejemplo se sugiere leer las secciones anteriores del uso básico de DOPPLER.
Consideraremos el siguiente problema ilustrativo de agendamiento. Tenemos dos destinos, planta y botadero y dos stocks preexistentes. El modelo de bloques se encuentra previamente valorizado. Deseamos agendar a 3 periodos considerando restricciones operacionales de transporte para ambos destinos y restricción de blending sobre un contaminante para la planta.
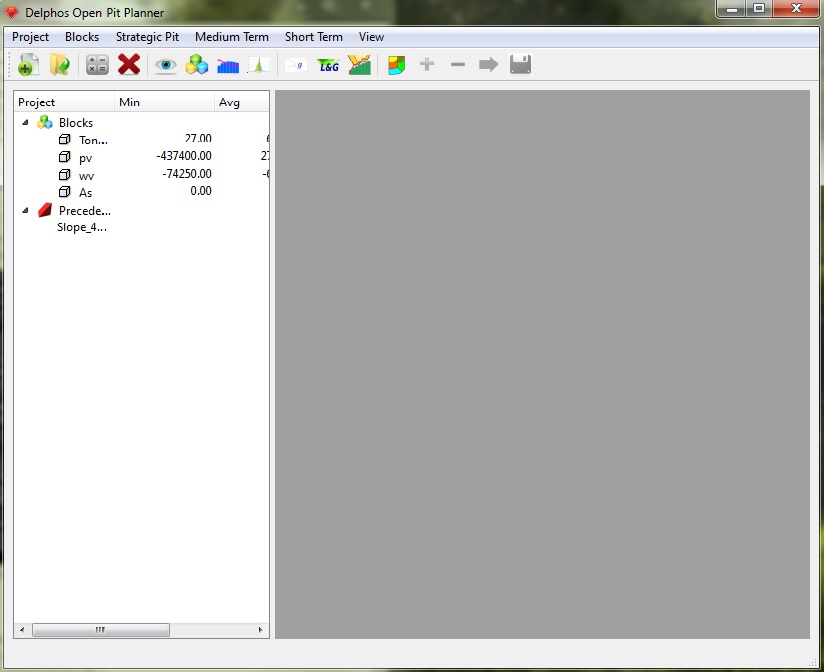
Partimos de un modelo ya cargado a DOPPLER que posee 4 columnas y un conjunto de precedencias de talud previamente creado, como se muestra en la siguiente figura
Para utilizar BOS2 necesitamos seleccionar Menu: Short Term-> Short Term Scheduler.
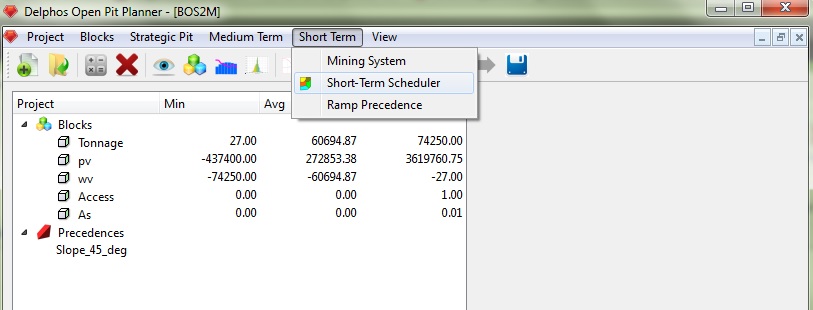
Al hacer esto un nuevo cuadro de trabajo se anclará al panel derecho y se activarán los últimos botones del menú de herramientas.
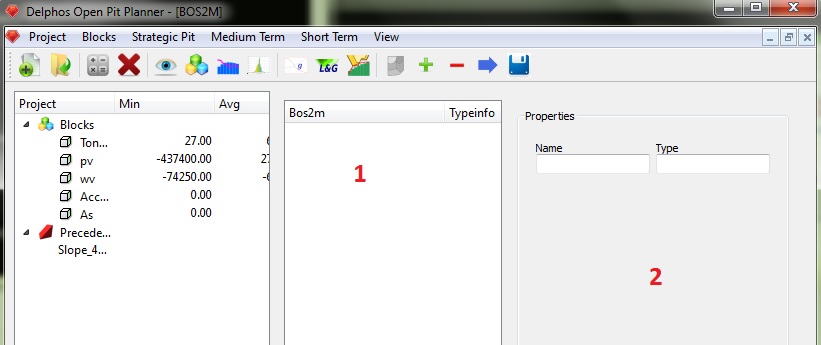
Como se aprecia en la figura, el nuevo cuadro consta, nuevamente de dos paneles. El primero (1) será en donde veremos el esquema de la instancia de BOS2 organizada en un sistema de dependencia tipo árbol-nodos y el segundo (2), el panel de la derecha, es aquel en donde podremos editar las diferentes propiedades de cada uno de los nodos de la instancia.
Para comenzar necesitamos crear un nodo raíz, el cual siempre será un nodo tipo Scheduling Instance. Para agregar/quitar nodos a la instancia se hace uso de los botones "+" y "-" en el menú de herramientas. Una cosa importante a señalar es que las opciones de nodos a agregar siempre varía según la selección actual en el panel del esquema (1), cuando no hay selección activa, por defecto sólo entrega la opción de agregar un nodo raíz.
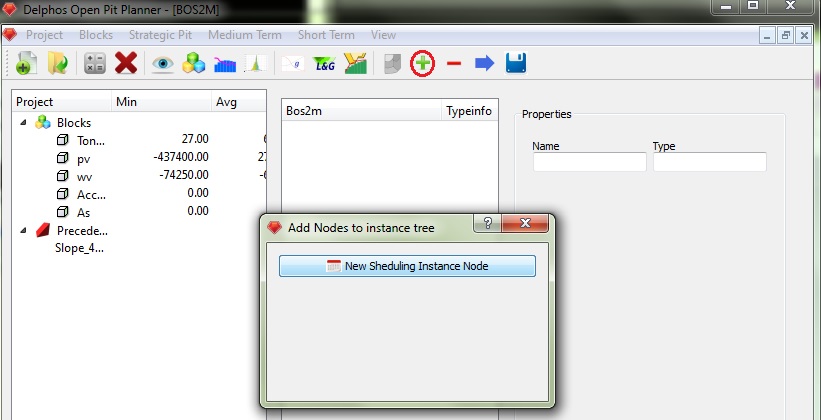
En la figura anterior se aprecia el cuadro de diálogo que aparecerá cada vez que presionamos el botón "+" en el menú de herramientas. En este caso, como la instancia está vacía, sólo propone un nodo raíz como opción. Al presionar el botón "New Scheduling instance" una serie de nodos se agregarán al esquema.
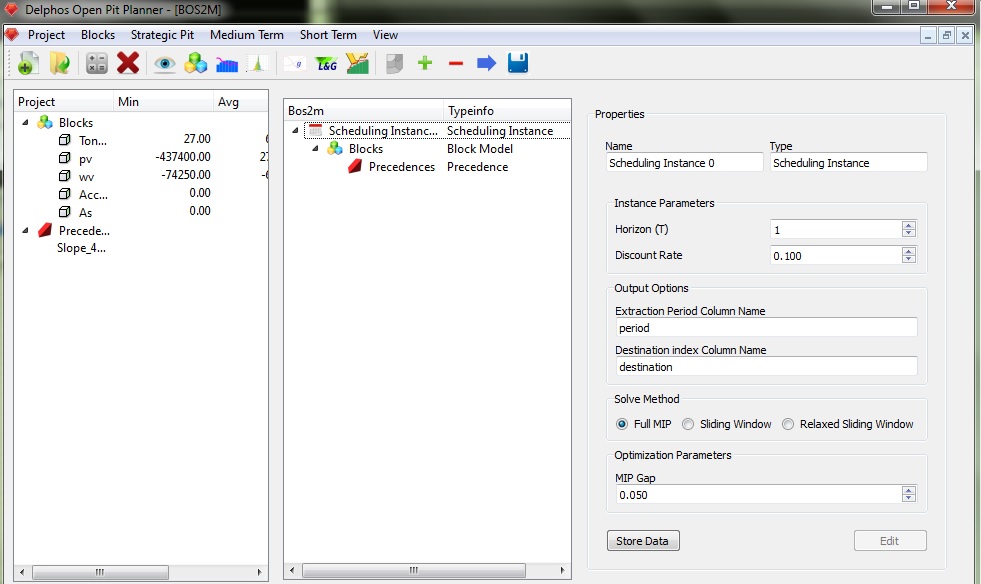
En la figura anterior podemos apreciar que al añadir el nodo raíz (Scheduling Instance) automáticamente se agregan un nodo hijo (Blocks) el cual corresponde al modelo de bloques cargado actualmente a DOPPLER y a su vez un nodo hijo a éste (Precedence) el cual corresponde a el (los) conjuntos de precedencias ya creados en DOPPLER. También puede apreciarse en el panel del esquema que la selección actual es la del nodo raíz, asi que lo que vemos en el panel derecho (propiedades) son los parámetros a asignar para el nodo raíz.
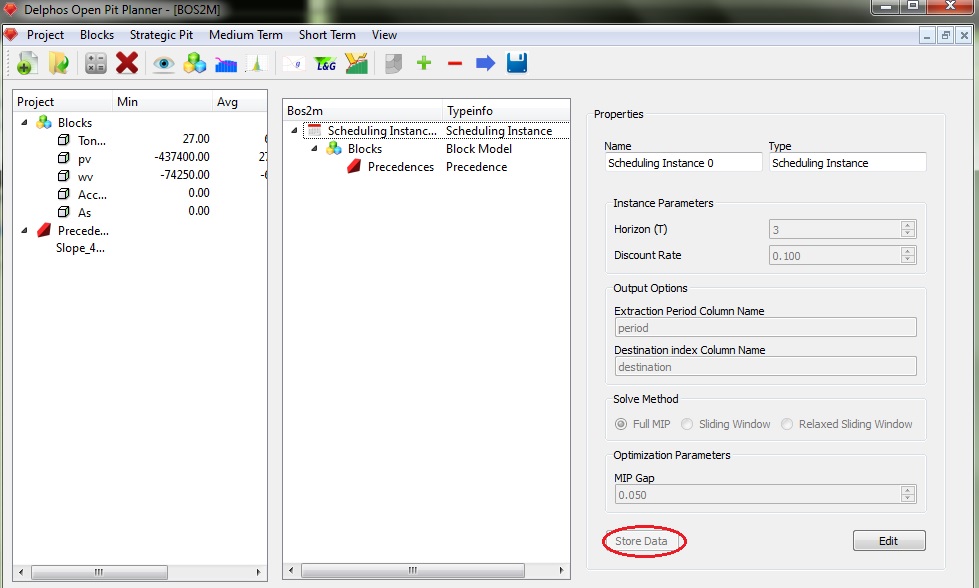
En el cuadro de propiedades, todos los nodos poseen un nombre editable y un tipo (el cual no es editable) el cual corresponde al tipo de nodo que es. Para efectos de este ejemplo, siempre dejaremos el nombre por defecto a los nodos que vayamos creando. Tal como establecimos en un principio, queremos agendar a 3 periodos, lo cual se ingresa en el cuadro "Horizon", consideraremos una tasa de descuento del 10% (cuadro "Discount Rate"), además una vez resuelta la instancia deseamos guardar el resultado como columnas en el modelo de bloques, los nombres para dichas columnas se especifican en el recuadro "Output Options". También tenemos a nuestra disposición elegir el método de resolución, el cual hemos dejado en "Full MIP", lo que quiere decir que resolveremos el problema de programación entera mixta completo. Finalmente, podemos especificar el GAP para la solver para el algoritmo de Branch and Cut. Una vez ingresados todos los datos debemos guardarlos en la instancia a través del botón "Store Data" al presionarlo se desactivarán todos los campos de edición. Si se desea editar algo se debe hacer presionar el botón "Edit" y luego de la edición, presionar "Store Data" nuevamente. Lo anterior es muy importante ya que para avanzar en la construcción de la instancia el módulo de BOS2 nos solicita que los datos previos se encuentren guardados. Cabe destacar que en todos los cuadros de propiedades existen estos dos botones (eventualmente con distintos nombres) en la misma posición que permiten guardar y editar los datos.
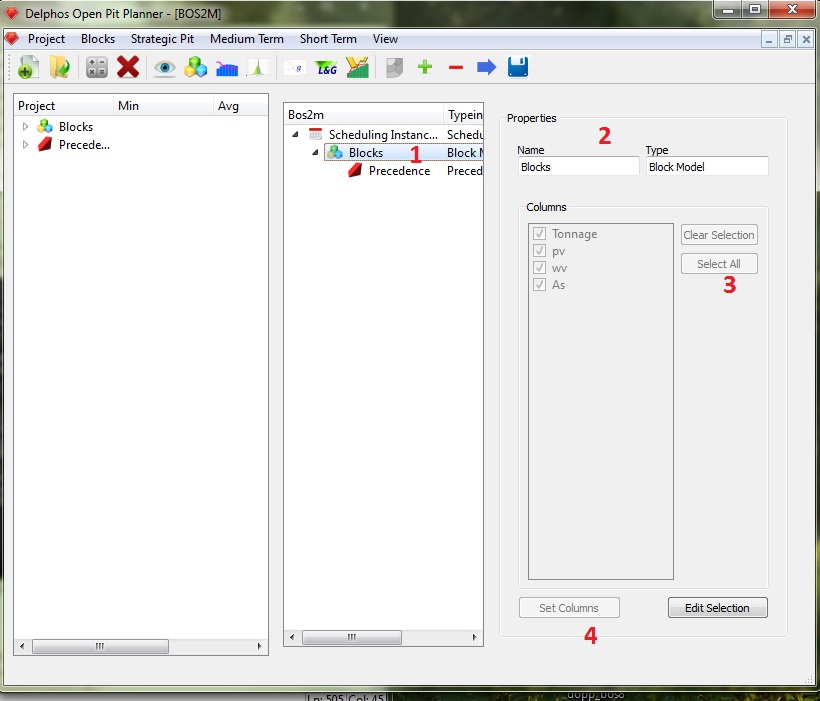
El siguiente paso será elegir las columnas del modelo de bloques que se utilizarán en la instancia. Para esto seleccionamos el nodo "Blocks" en el panel de esquema (1), lo cual nos activará las propiedades de edición del nodo. Dejamos el nombre del nodo en el valor por defecto (2) y luego, para nuestro ejemplo, seleccionamos todas las columnas del modelo vía el botón "Select All" (3), finalmente guardamos los datos presionando el botón "Set Columns" (4). Este paso es muy importante ya son estas columnas que se mostrarán como opciones en todos los nodos que hemos de crear de aquí en adelante en el resto de la instancia.
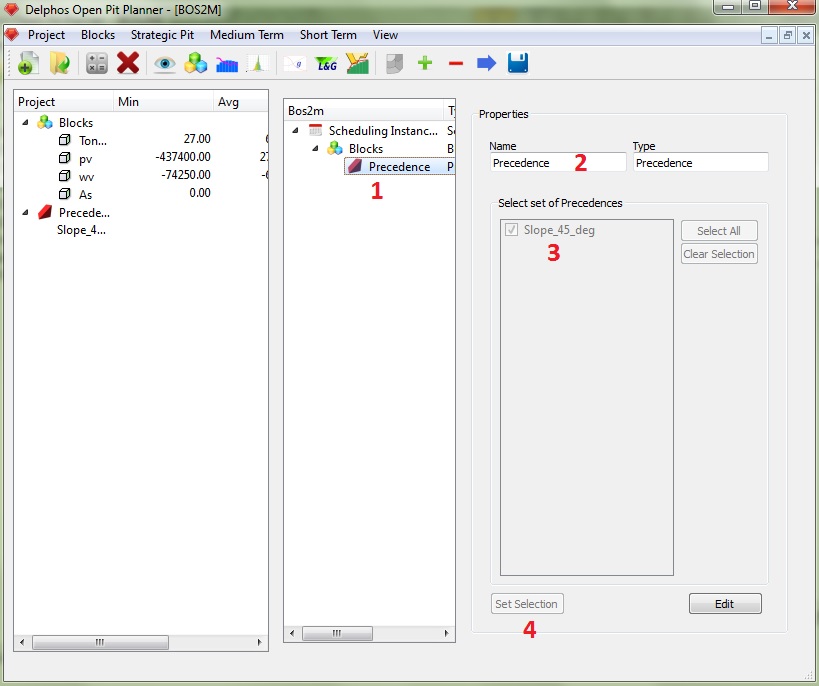
En la figura anterior se muestra como seleccionar las precedencias para nuestra instancia. Seleccionamos el nodo "Precedence" en el panel de esquema (1), luego podemos dar un nombre al nodo (2) para luego seleccionar de la lista que aparece en cuadro (3) los conjuntos a seleccionar. Una vez realizada la selección presionamos "Set Selection" para guardar los datos. Cabe destacar que en esta lista veremos todos los conjuntos de precedencias creados previamente al inicio del módulo BOS2 y podemos seleccionar todos los que queramos.
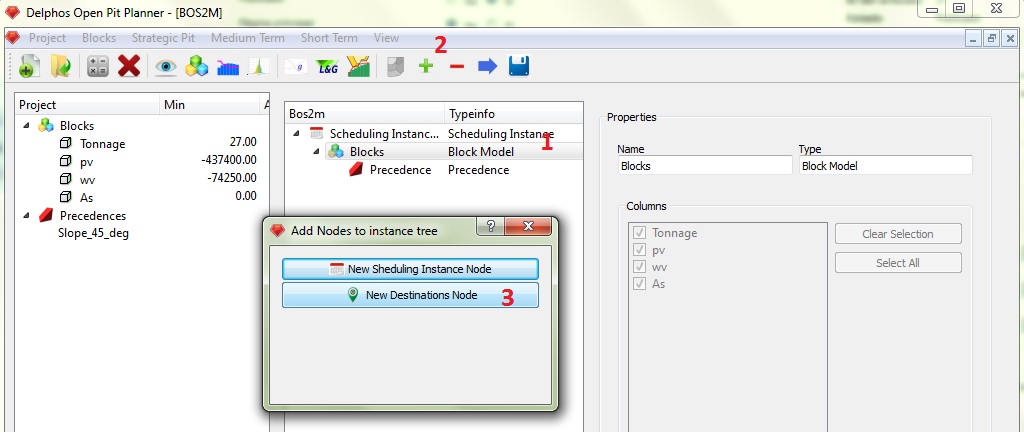
El siguente paso es generar destinos para nuestra instancia. Como los destinos deben tener asociados columnas del modelo de bloques, el nodo de destinos se descuelga del nodo "Blocks". Entonces el primer paso es seleccionar el nodo "Blocks" en el panel de esquema (1), luego presionamos el botón "+" del menú de herramientas (2), luego aparecerá el diálogo de agregación en el cual vemos que ahora disponemos de la opción de generar nodos de destinos (3). Al presionar el botón "New Destinations Node" se agregará el nodo bajo el nodo "Blocks".
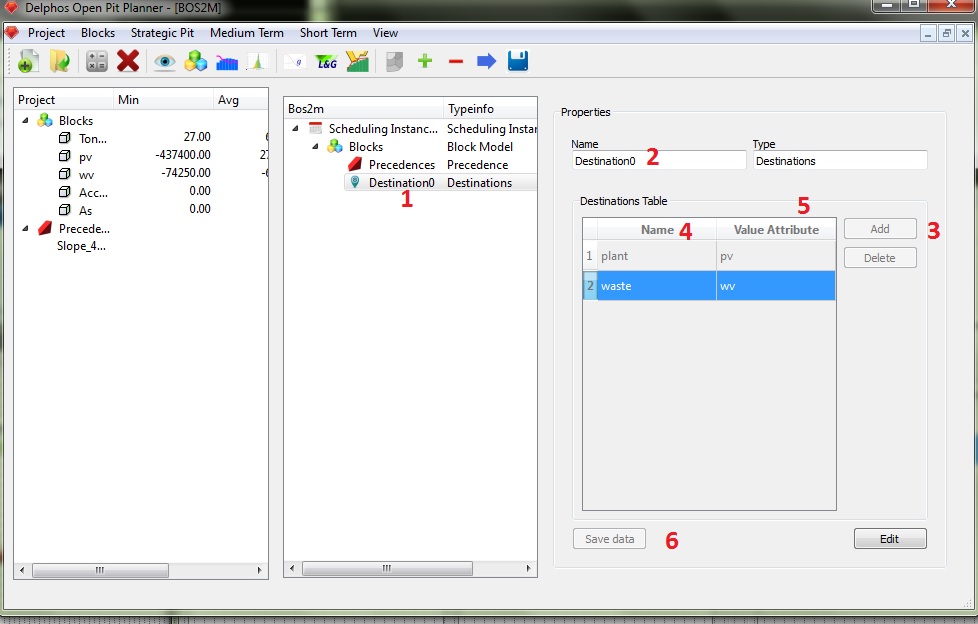
En la figura anterior vemos el nodo agregado. Para proceder con la creación de los destinos debemos seleccionar el nodo de destinos recién agregado (1) y seleccionar un nombre para el nodo (2). Luego podemos agregar los destinos a considerar en la tabla haciendo uso del botón "Add" (3), al presionar dicho botón un nueva fila se agrega a la "Destinations Table" con valores por defecto. Como establecimos en un principio, deseamos utilizar dos destinos: planta y botadero, por lo que presionamos el botón "add" dos veces y procedemos a editar los campos con los valores deseados (4). La tabla posee dos campos, el primero corresponde al nombre del destino ("Name") y el segundo al nombre de la columna del modelo de bloques que contiene los valores de cada bloque al ser enviados a dicho destino ("Value Attribute"). En todas las tablas de edición que veremos en el módulo BOS2 el sistema de edición es el mismo: hay que presionar una vez sobre la celda deseada y un editor adecuado a cada tipo de celda se activará. En algunos casos son lineedits en otros casos comboboxes y en otros spinboxes numéricos. Una vez ingresados los datos (en nuestro ejemplo, como puede verse en la figura los valores de la planta y el botadero son las columnas "pv" y "wv" respectivamente) debemos guardar los datos usando el botón "Save data" (6).
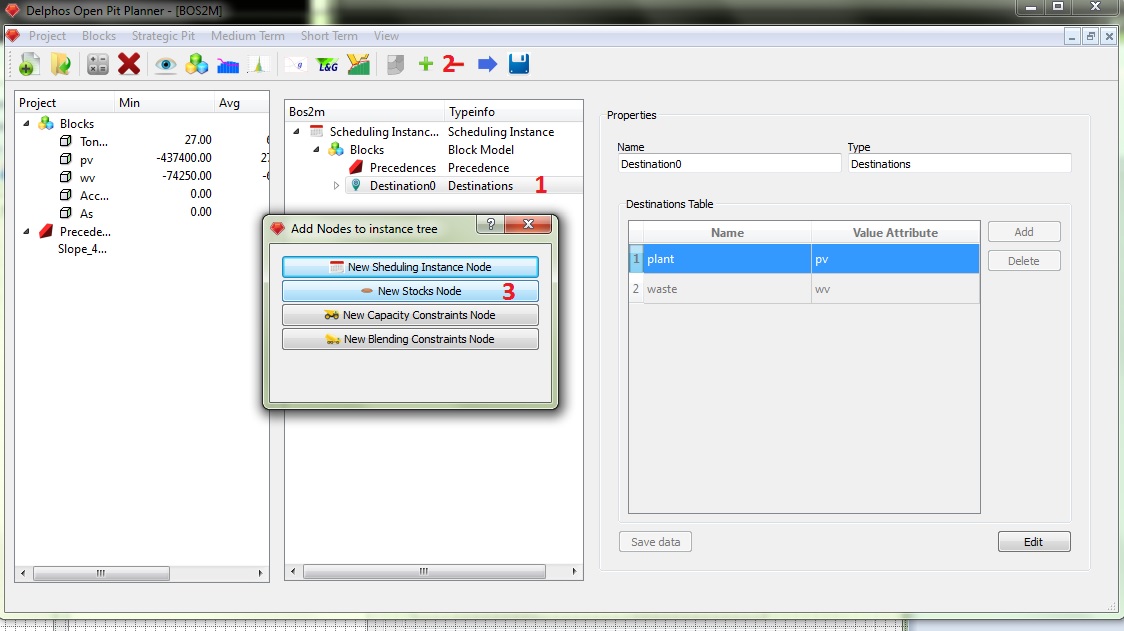
El paso siguiente, será crear los stocks preexistentes para nuestro problema de agendamiento. Como los stocks necesitan información tanto del modelo de bloques como de los destinos, el nodo de stocks se descuelga de los nodos de destinos. Entonces, partimos seleccionado el nodo de destinos ya creado (1) y luego presionamos el botón "+" del menú de herramientas (2). Luego aparecerá nuestro cuadro de diálogo en donde vemos 3 nuevas opciones. La que nos interesa de momento es "New Stocks Node" (3). Al presionarla se agregará un nodo tipo "Stocks" bajo el nodo de destinos seleccionado.
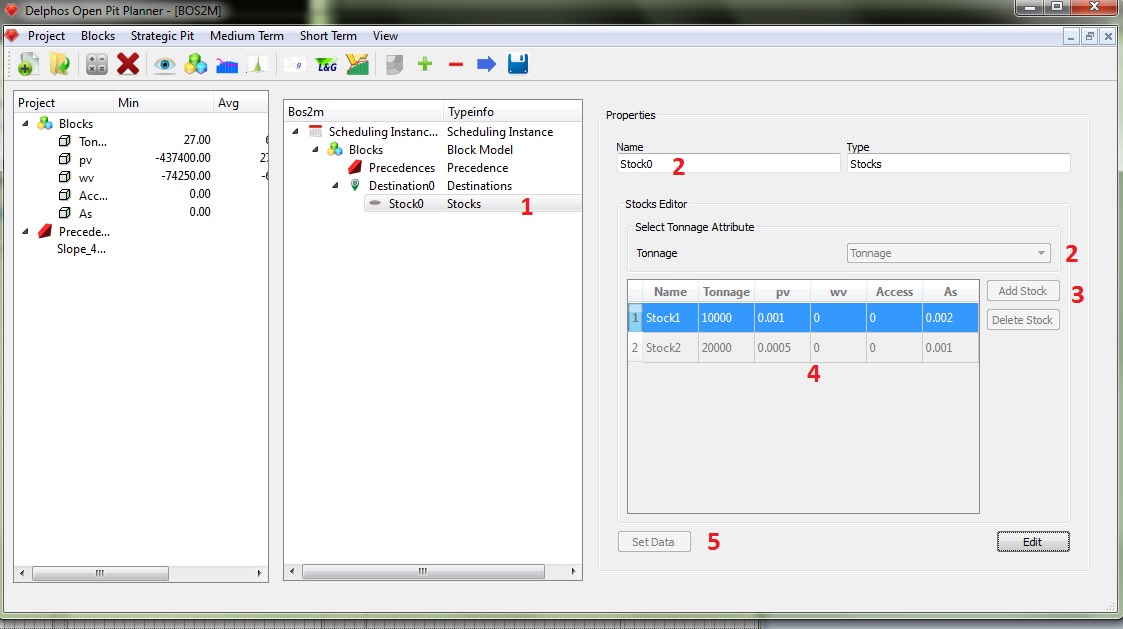
Para crear nuestros stocks necesitamos seleccionar el nodo de "Stocks" en el panel de esquema. Se activará el panel de propiedades y en éste podemos ingresar os datos como se muestra en la figura. En primer lugar podemos darle un nombre a nuestro nodo (1), luego debemos seleccionar la columna del modelo de bloques que corresponde a la columna de tonelaje (2) y luego podemos agregar la cantidad de stocks deseada mediante el botón "Add Stock" (3). En nuestro caso queremos dos stocks, por lo que presionamos el botón dos veces y procedemos a editar cada uno de los campos que aparecen en la tabla. Nótese que aparte del nombre ("Name") y el valor del tonelaje inicial para los stocks ("Tonnage") el resto de los campos corresponden a las columnas seleccionadas en el nodo "Blocks" para nuestra instancia. Claramanete entre ellas deben estar las columnas de valor para los destinos. Ya con los datos ingresados podemos guardar (5) y seguir con la construcción de la instancia.
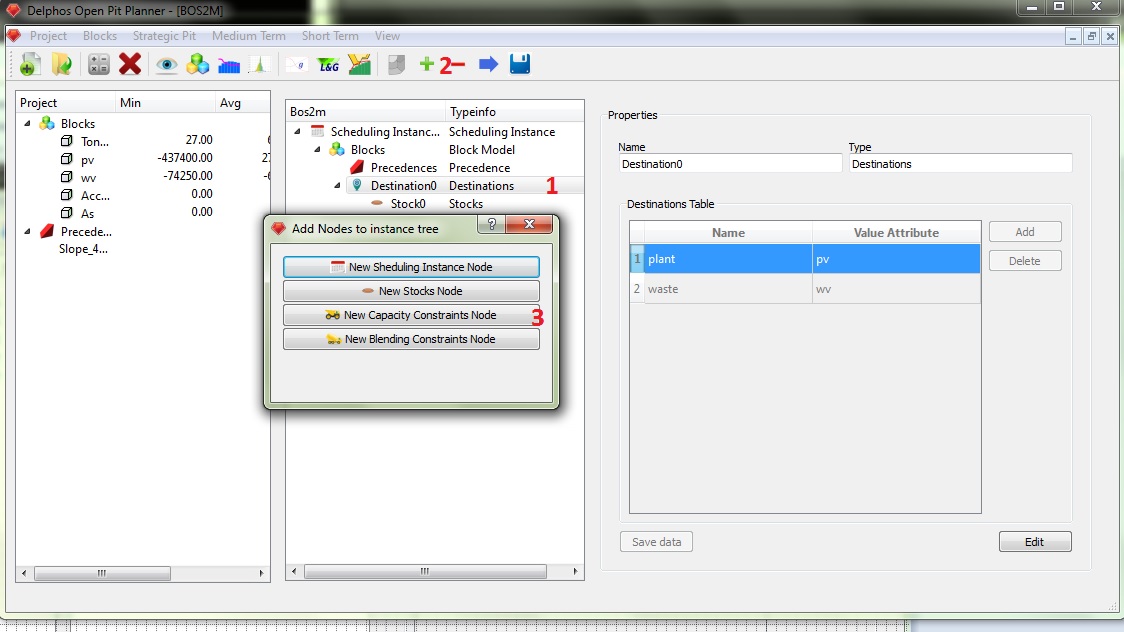
Ahora necesitamos generar restricciones de capacidad para nuestro problema. Las restricciones de capacidad necesitan información tanto del modelo de bloques como de los destinos, por lo que el nodo de capacidades se descuelga del nodo de destinos. Seleccionamos el nodo de destinos (1), presionamos "+" en el menú de herramientas (2) y seleccionamos "New Capacity Constraints Node" (3).
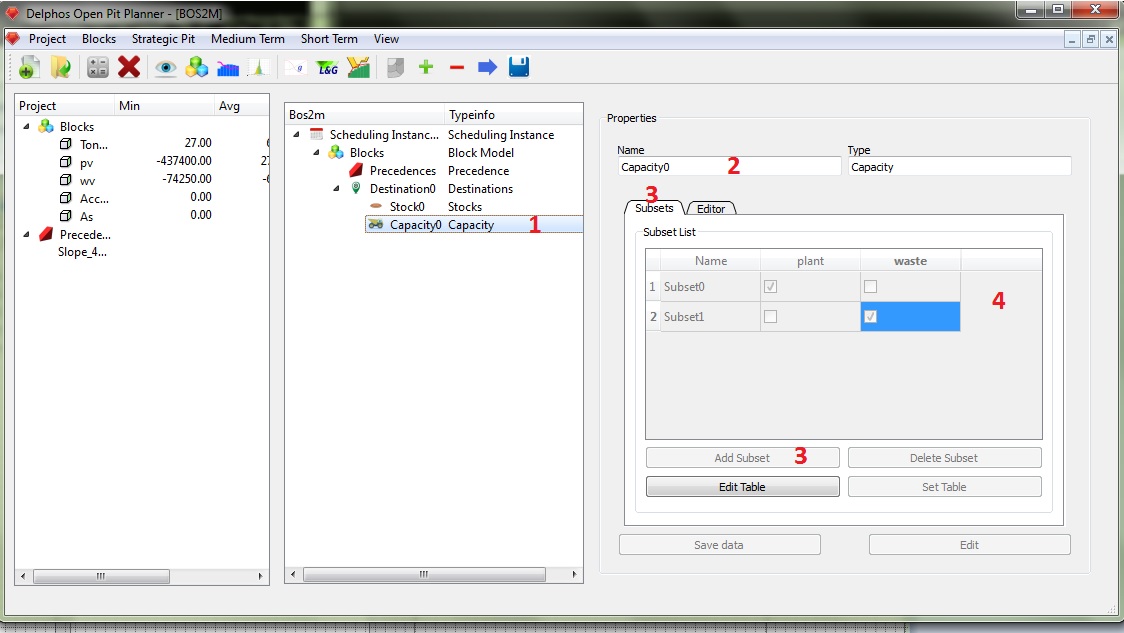
Para ingresar los datos seleccionamos el nodo recién creado del panel de esquema (1). Le damos un nombre al nodo (2) y seleccionamos la pestaña "Subsets" (3). Esta pestaña nos permite generar todos los subconjuntos del conjunto de destinos sobre los cuales las restricciones de capacidad operarán. Lo anterior se debe a que, por ejemplo, una restricción de capacidad puede involucrar sólo a un destino o a todos los disponibles. En nuestro caso las restricciones operaran para cada destino por separado, por lo que necesitamos crear 2 subconjuntos haciendo uso del botón "Add Subset" (3), luego marcamos los destinos que componen cada subconjunto y le damos un nombre a cada uno de éstos (4). Una vez finalizado presionamos "Set Table" para setear los datos.
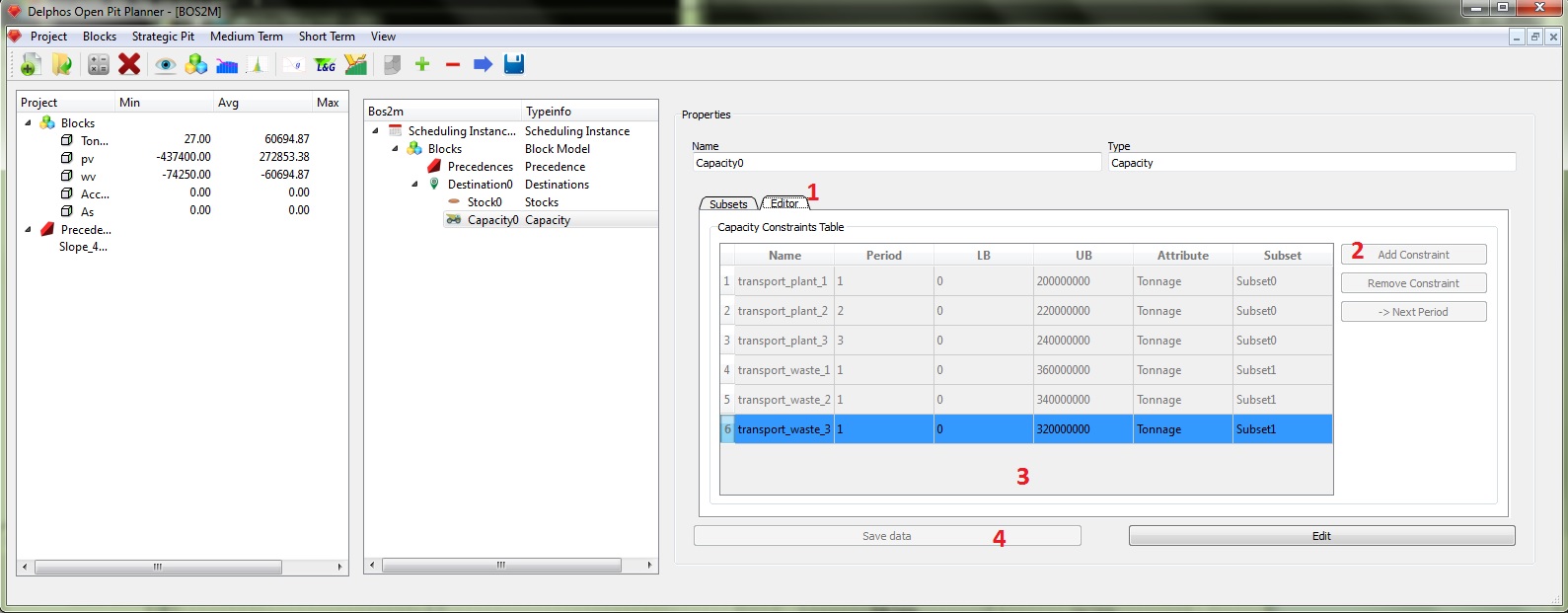
Luego podemos pasar a la siguiente pestaña. Seleccionamos la pestaña "Editor" (1) y agregamos la cantidad de restricciones deseadas. En nuestro caso queremos imponer restricciones de transporte en tonelaje para ambos destinos en cada periodo, lo que da un total de 6 filas en la tabla. Presionamos "Add Constriaint" 6 veces (2) y procedemos a llenar la información en los campos (3). El campo "Name" corresponde al nombre de la restricción, "Period" es el periodo en donde está activa, "LB" y "UB" son las cotas inferior y superior para la restricción respectivamente, "Attribute" es el atributo a sumar en la restricción y "Subset" es el nombre del subconjunto creado en la pestaña anterior sobre el cual aplica la restricción. Con los datos ya ingresados presionamos "Save data" (6) y podemos proseguir al nodo de Blending.
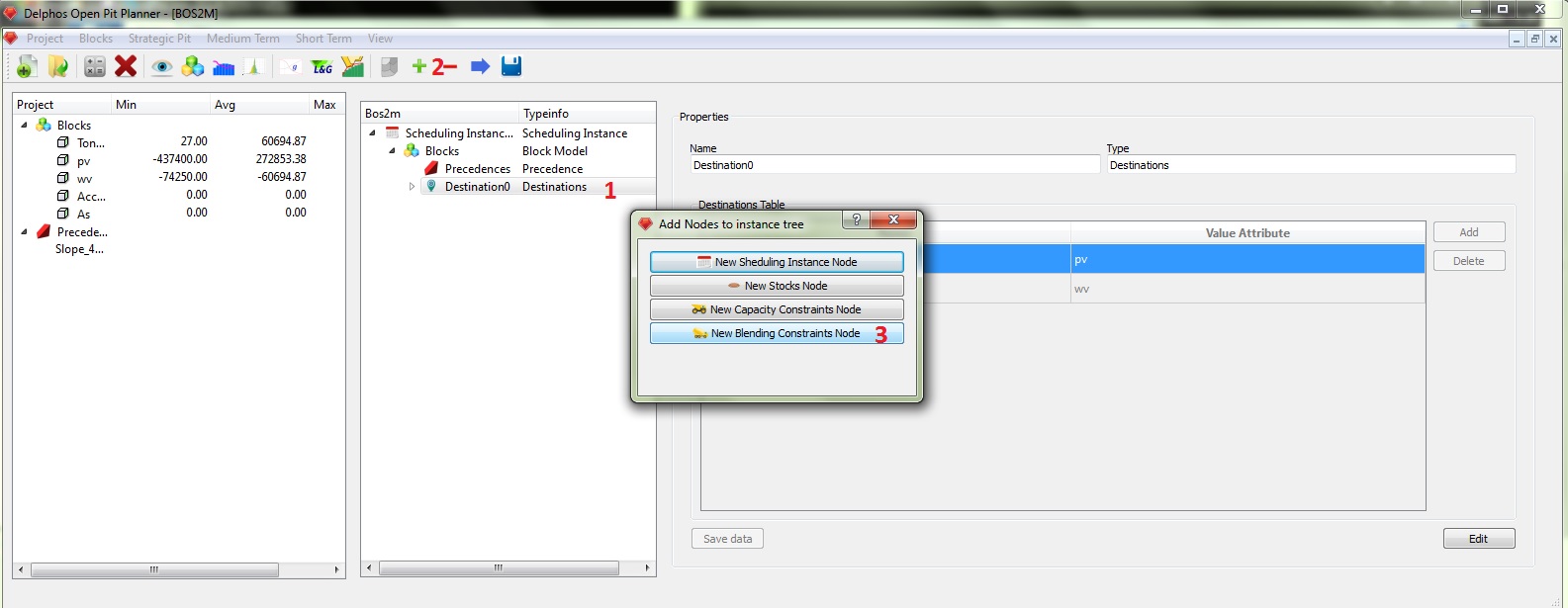
Ahora queremos agregar restricciones de Blending a nuestra instancia. para esto contamos con un columna en el modelo de bloques llamada "As" que representa el porcentaje de arsénico en los bloques. Entonces nos interesa que los bloques enviados a planta en cada periodo no excedan una cierta concentración de arsénico en promedio. Nuevamente, como para la confección de estas restricciones necesitamos información tanto del modelo de bloques como de los destinos, el nodo de Blending se descuelga de un nodo de destinos.
Seleccionamos el nodo de destinos (1), luego presionamos el botón "+" del menú de herramientas (2) y finalmente seleccionamos "New Blending Constraints Node" desde el cuadro de diálogo (3).
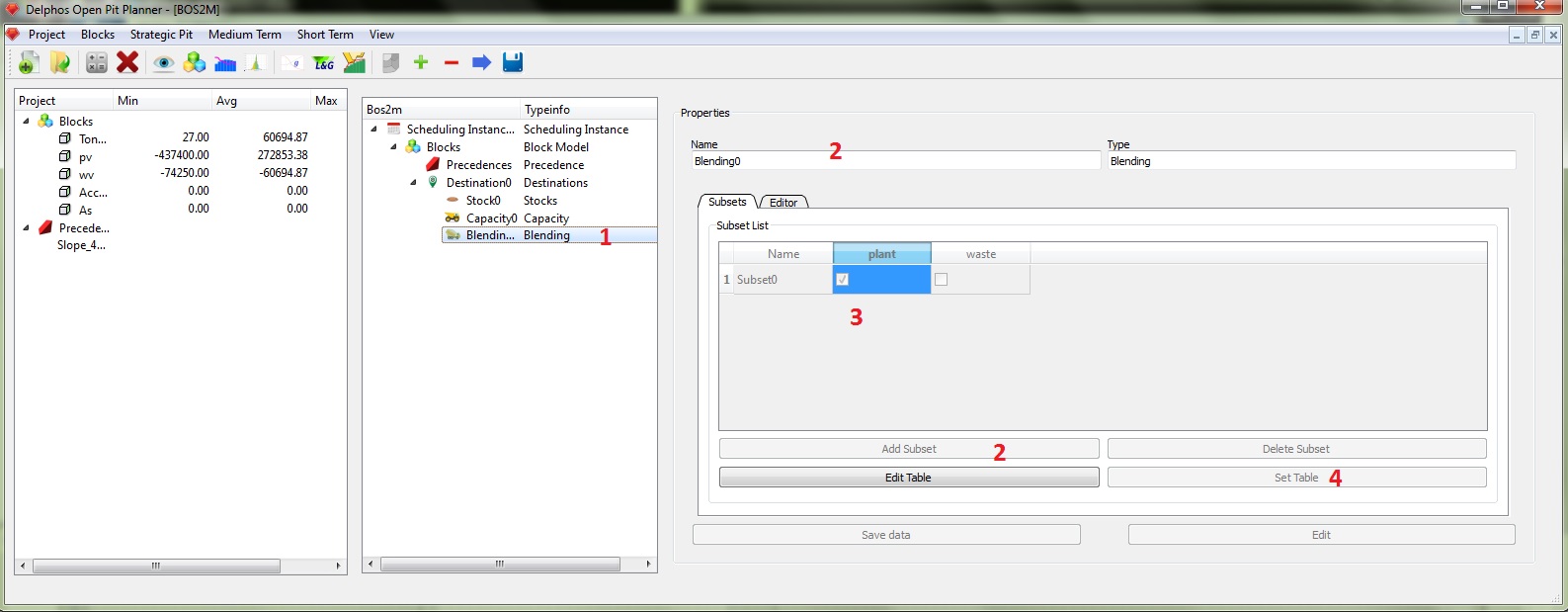
El esquema de edición es completamente análogo al caso de las capacidades. en la figura anterior generamos los subconjuntos. En este caso sólo nos interesa la planta, por lo que necesitamos sólo un subconjunto.
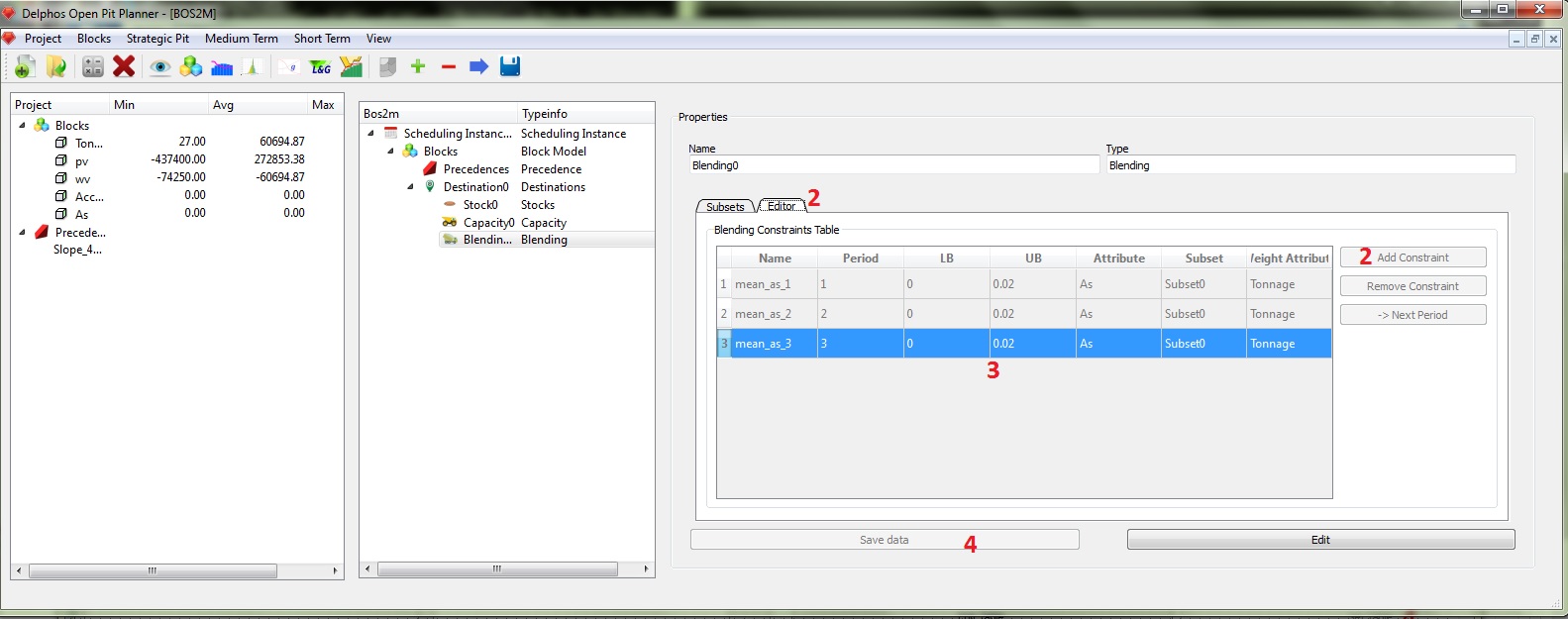
Nuevamente la generación de los datos es análoga al caso de las capacidades, pero en este caso poseemos de un campo adicional "Weight Attribute" el cual representa el ponderador sobre el cual se calcula el promedio sobre el periodo. En nuestro ejemplo queremos fijar límites para el arsénico para la planta en todos lo periodos por lo que tenemos 3 restricciones que agregar. Finalmente, como ya es usual guardamos los datos y hemos finalizado la generación de nuestra instancia.
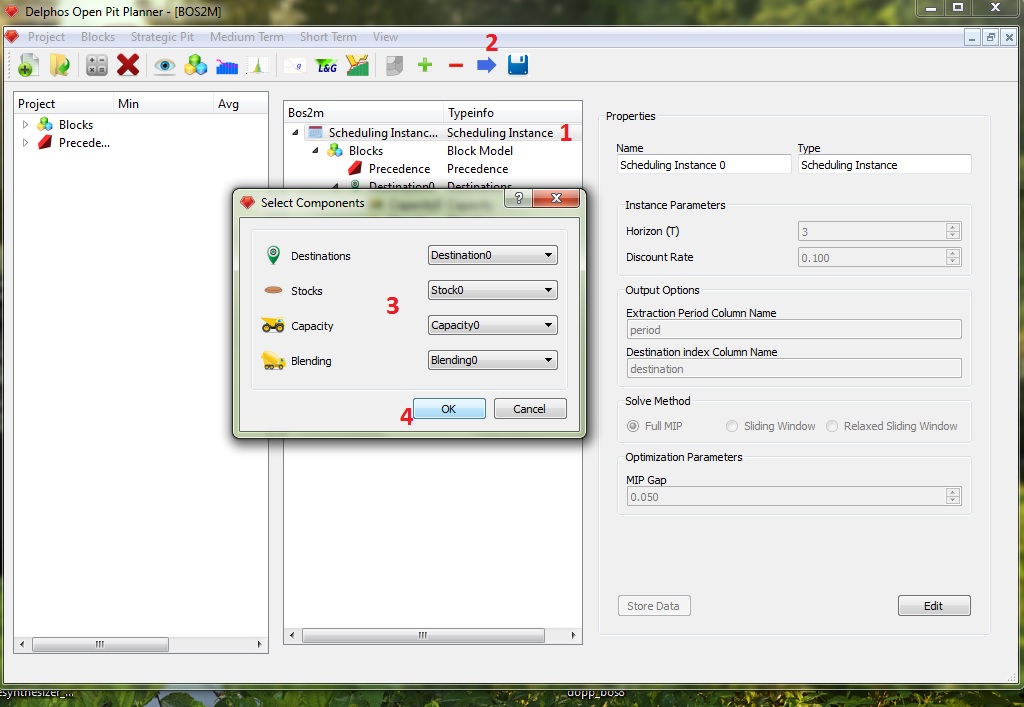
Para resolver nuestra instancia, debemos seleccionar el nodo raíz asociado en el panel de esquema (1). Luego presionamos en la flecha azul en el menú de herramientas (2). Nos aparecerá un cuadro de diálogo llamado "Select Components" en el cual para cada tipo de nodo debemos seleccionar los que compondrán nuestra instancia. Esto se debe a que, como puede notarse a través del ejemplo, podemos generar múltiples nodos de cada tipo con diferentes datos y finalmente, seleccionar en este paso cuáles consideraré para resolver la instancia. Seleccionamos los nombres de nuestros nodos creados (4) y presionamos "Ok".
En este momento comienza el proceso de optimización según los parámetros especificados en el nodo raíz. El cual, dependiendo del método de resolución puede tomar un cantidad considerable de tiempo. Durante este proceso la aplicación se vuelve inactiva y sólo vuelve a operar una vez finalizado el proceso.
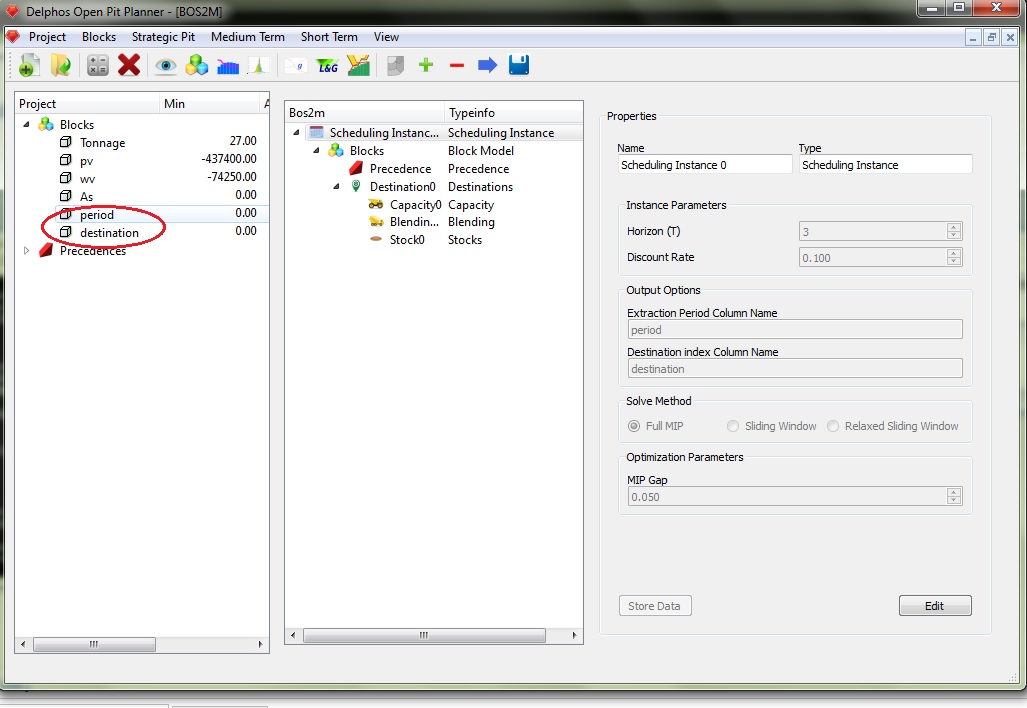
Al finalizar el proceso podremos ver las nuevas columnas generadas en el modelo de bloques con los nombres que dispusimos en el cuadro de propiedades del nodo raíz, como se aprecia en la figura anterior. De aquí en adelante se puede visualizar los datos obtenidos mediante las herramientas de DOPPLER (véase "Herramientas de visualización") o bien exportarlos para algún otro tipo de análisis acorde.